
最近的一个横向中涉及对图像进行降采样的问题,最近两周实现和对比了一些降采样的方法,在本文中进行归纳总结。
本文的主要内容包括:1.介绍几种常见的降采样方法。2.对比不同方法的性能。3.基于计算着色器实现区域平均。
定义
图像降采样(Image Downsampling)是指通过减少图像的像素数量来降低图像分辨率的过程。具体来说,它是将高分辨率的原始图像转换为较低分辨率的图像,同时尽可能保持图像的视觉质量和关键信息。
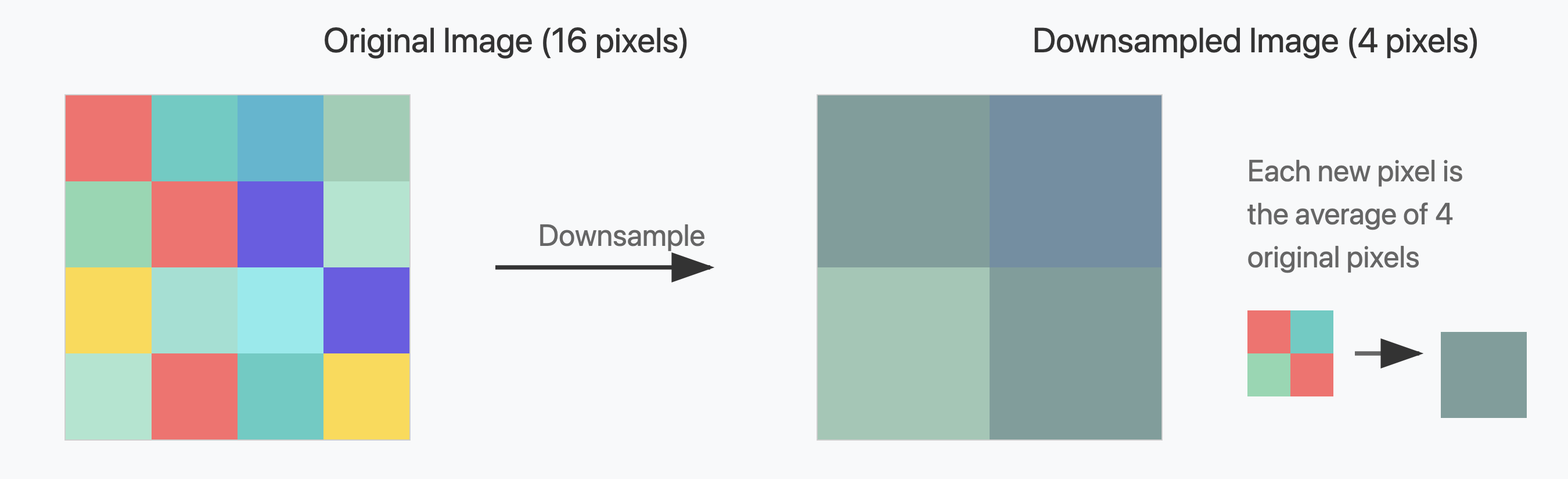
图 1:区域均值降采样。
常见的图像降采样方法包括:
- 最近邻插值 选择最接近的像素值
- 双线性插值 使用周围4个像素的加权平均
- 双三次插值 使用周围16个像素的加权平均
- 区域平均 计算采样区域内所有像素的平均值
问题目标
- 将图像的分辨率降低到 $\frac{W}{2^n} \times \frac{H}{2^n}$。
- 在保证图片质量的前提下,尽可能提高计算速度。
- 使用C++、OpenGL或Vulkan实现。
下采样方法
为了平衡计算速度和图片质量,本文主要研究双线性插值或区域平均。
双线性插值
图形API中的双线性插值
在OpenGL或Vulkan等图形API中,双线性插值被广泛的支持,例如在OpenGL中,可以使用glTexImage2D函数来创建一个纹理,并指定GL_LINEAR作为纹理过滤器,从而在片段着色器中使用双线性插值对该纹理进行采样。除了GL_LINEAR外,还包括:
GL_NEAREST:最近邻插值GL_NEAREST_MIPMAP_LINEAR:根据bias参数选择两个mipmap层,mipmap层内部进行最近邻插值,mipmap层之间使用线性插值。-
GL_NEAREST_MIPMAP_NEAREST:选择最近的mipmap层,在单个mipmap中最近邻插值。 GL_LINEAR_MIPMAP_NEAREST:选择最近的mipmap层,在单个mipmap中双线性插值。GL_LINEAR_MIPMAP_LINEAR:根据bias参数选择两个mipmap层,mipmap层内部进行双线性插值,mipmap层之间使用线性插值。
在Vulkan中,将图像绑定到描述符集时,可以为该图像创建采样器,可以为采样器指定类似于前文OpenGL提供的采样参数,具体包括:
VK_FILTER_NEAREST:最近邻插值VK_FILTER_LINEAR:双线性插值
如果开启mipmap,则可以指定:
VK_SAMPLER_MIPMAP_MODE_NEAREST:对mipmap进行最近邻插值VK_SAMPLER_MIPMAP_MODE_LINEAR:对mipmap进行双线性插值
双线性插值理论
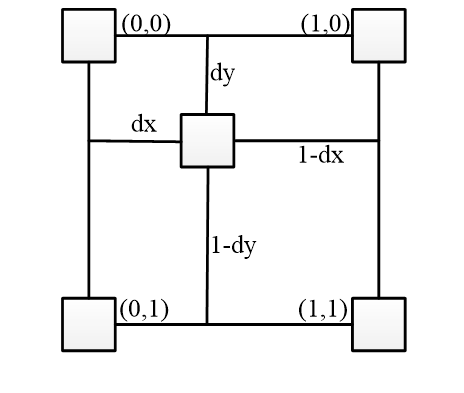
图 2:双线性插值。
双线性插值需要使用最近的四个像素进行插值,计算公式如下:
\(I(x, y) = (1 - dx) * (1 - dy) * I(0, 0) + dx * (1 - dy) * I(1, 0) + (1 - dx) * dy * I(0, 1) + dx * dy * I(1, 1)\)
其中,$I(x, y)$是插值后的像素值,$I(0, 0)$、$I(1, 0)$、$I(0, 1)$、$I(1, 1)$是最近的四个像素值,$dx$和$dy$是插值点相对于最近四个像素点的偏移量。
将双线性插值应用于降采样时,如果将分辨率降低为原始分辨率的$\frac{1}{2}$,那么等价于对四个像素进行区域平均,即:
\(I(0.5,0.5) = (1-0.5) * (1-0.5) * I(0, 0) + 0.5 * (1-0.5) * I(1, 0) + (1-0.5) * 0.5 * I(0, 1) + 0.5 * 0.5 * I(1, 1) \\
I(0.5,0.5) = \frac{I(0, 0) + I(1, 0) + I(0, 1) + I(1, 1)}{4} \phantom{* (1-0.5) * I(0, 0) + 0.5 * (1-0.5) * I(1, 0) + (1-0.5) * 0.5 * I(0, 1) + 0.5 * 0.5 * I(1, 1)}\)
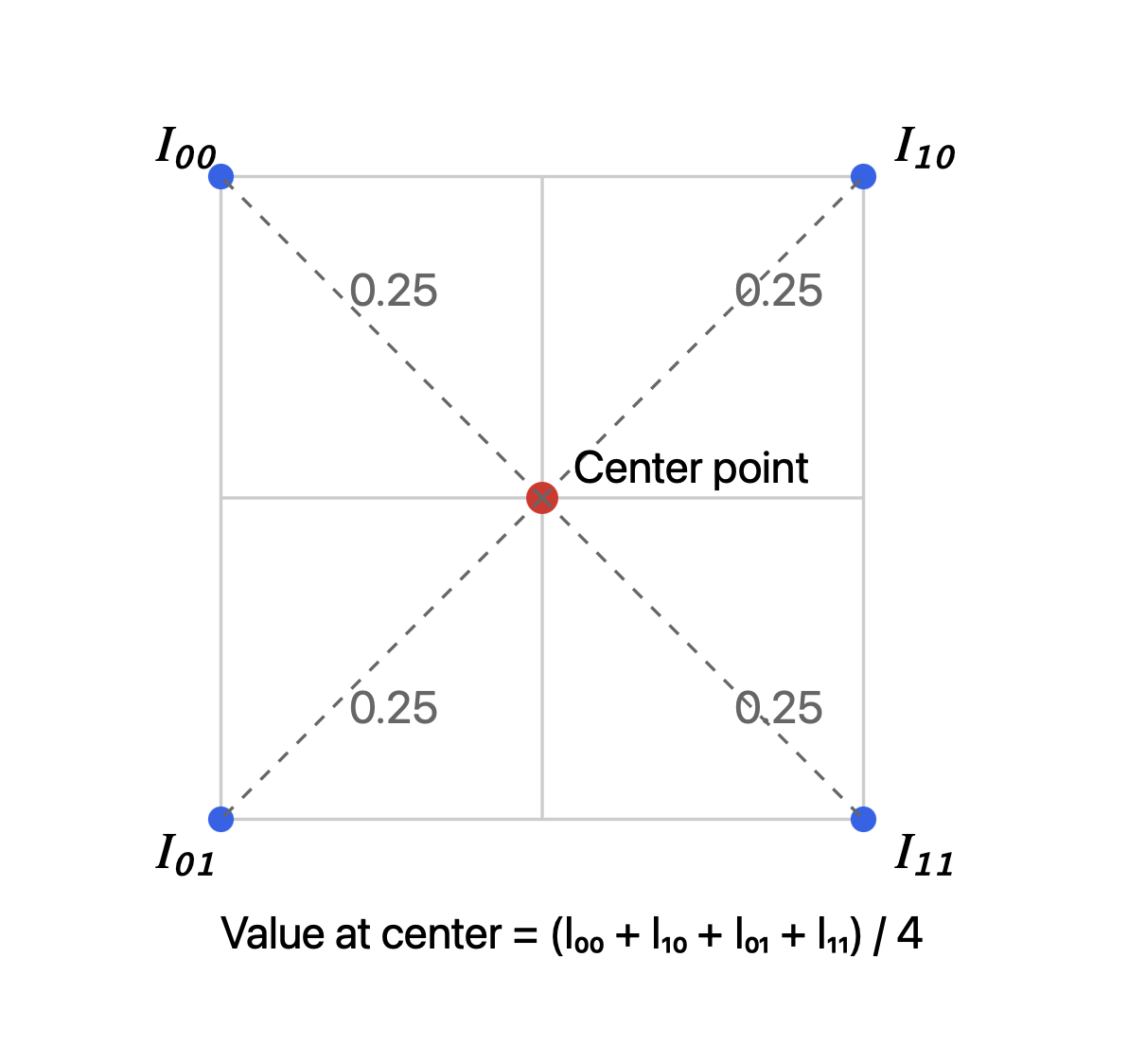
图 3:图像分辨率降低一半时,双线性插值等价于区域平均。
然而,当降采样比率较大时($\frac{width_{original}}{width_{downsampled}} > 2$),双线性插值会”遗漏”一些像素,从而带来图像质量的显著损失。如下图所示,蓝色的像素是原始图像中的像素,深色的像素是降采样后对应回原图的区域,橙色圆形是该区域的中心,对橙色圆形进行双线性插值时参与的只有蓝色圆形所示的点,其他像素被”遗漏”。
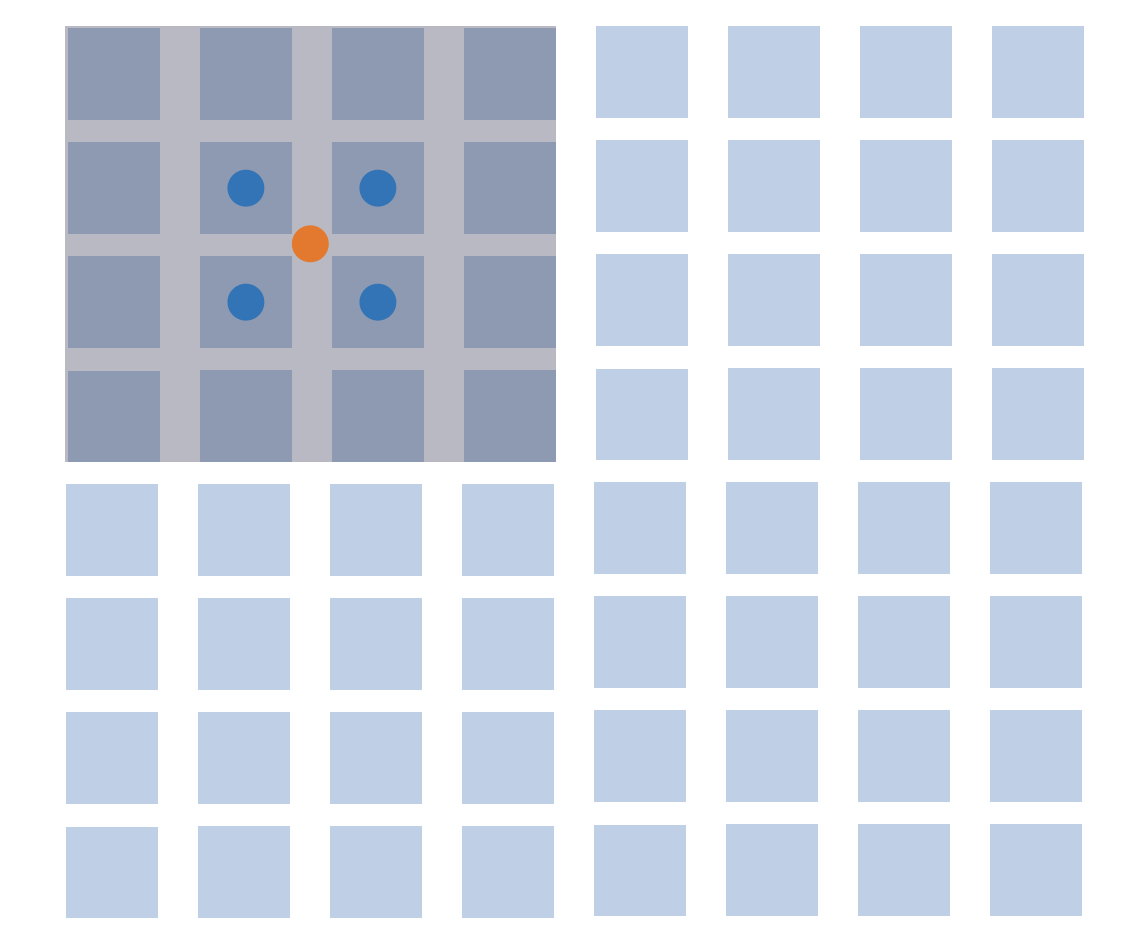
图 4:降采样样比率较大时,双线性插值会"遗漏"一些像素。
因此,为了保证降采样图像的质量,逐级降采样是更好的选择。所谓逐级降采样,是指将图像先降采样到$\frac{1}{2}$,再降采样到$\frac{1}{4}$,再降采样到$\frac{1}{8}$,以此类推。

图 5:逐级降采样。
这种逐级降采样的方式非常适合在图形管线中实现。在OpenGL中,我们可以通过两种方式来实现:
- 使用
glGenerateMipmap函数自动生成mipmap序列,这是最简单直接的方法 - 将原始图像作为输入纹理,通过多次渲染并利用双线性插值采样到更小的目标图像上,逐步完成降采样过程
与OpenGL不同,Vulkan没有提供类似glGenerateMipmap的便捷函数。在Vulkan中,我们需要通过重复调用vkCmdBlitImage命令来手动生成每一级mipmap。虽然这种方式需要更多的代码,但也给了开发者更大的灵活性和控制权。
下文将对比这三种方式的时间和优缺点。
区域平均理论
区域平均是一种简单直观且计算高效的图像降采样方法。它通过以下步骤实现图像的降采样处理:
- 根据目标图像尺寸,将原始图像划分为多个大小相等、互不重叠的矩形区域
- 对每个矩形区域内的所有像素值进行算术平均计算
- 将计算得到的平均值赋给降采样后图像中对应位置的像素
这种方法的一大优势在于其灵活性: 它可以通过单次计算过程将图像直接降采样到任意目标尺寸,而不需要多次迭代。这种特性使其在某些场景下具有明显的性能优势。
实现和对比
glGenerateMipmap
直接调用函数即可。
逐级降采样
思路:输入纹理A,将纹理B作为帧缓冲的颜色附件,纹理B的分辨率是纹理A的$\frac{1}{2}$。
准备阶段:
width, height
For mipmapLevel = 0 to mipmapLevelMax:
Create Texture[mipmapLevel] with width ,height
Create Framebuffer[mipmapLevel] with Texture[mipmapLevel]
width, height = width / 2, height / 2
渲染阶段:
For mipmapLevel = 0 to mipmapLevelMax:
Bind Framebuffer[mipmapLevel]
Bind Texture[mipmapLevel-1]
Render
Vulkan Mipmap生成
重复调用vkCmdBlitImage命令,将mipmapLevel-1的图像blit到mipmapLevel。
时间统计方法
CPU时间
CPU时间是指CPU侧执行代码的时间(包含CPU侧的处理,指令提交到GPU,GPU执行,GPU返回结果的时间),即资源分配和GPU执行的时间。
1.使用std::chrono::high_resolution_clock::now()和std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()来统计时间。
2.使用Nvidia Nsight Compute来统计CPU时间。
GPU时间
GPU时间是指GPU执行该指令提交到GPU的任务的时间。
1.使用Querypool。
2.使用Nvidia Nsight Compute的GPU Trace Profiler来统计GPU时间。
结果
输入2048*2048的图像。
第一帧:
| 方法 | CPU时间(ms) | GPU时间(ms) |
|---|---|---|
| glGenerateMipmap | 10.8 | 2.2 |
| 逐级降采样 | 9.8 | 1.4 |
| Vulkan Mipmap | 1.9 | 1.5 |
注:
- 逐级降采样中,CPU时间是指创建帧缓冲和纹理的时间。
- VUlkan Mipmap生成的CPU时间只包含blit指令产生的CPU时间(统计该Command提交到返回到时间),不包含纹理图像创建的时间(VUlkan在创建纹理图像时需要指定Mipmap level,并为之分配内存)。
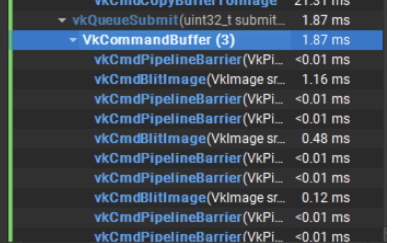
图 6:Vulkan降采样指令返回时间。
第二帧:
| 方法 | CPU时间(ms) | GPU时间(ms) |
|---|---|---|
| glGenerateMipmap | 2.4 | 2.1 |
| 逐级降采样 | 9.3 | 1.5 |
| Vulkan Mipmap | 1.8 | 1.5 |
从上述结果中可以看出,第一次调用glGenerateMipmap时,CPU时间较长,而Vulkan Mipmap的CPU时间较短,这可能是因为glGenerateMipmap在第一次调用时需要进行一些初始化工作,而Vulkan Mipmap在第一次调用时已经完成了纹理图像的创建。
就GPU侧的速度而言,逐级降采样和Vulkan Mipmap的速度相近,二者都快于glGenerateMipmap。
glGenerateMipmap函数对我们而言就像是一个黑盒子,第二帧的时间显著减少,是否意味着glGenerateMipmap函数在第二次调用时实际没有执行任何操作?为了解答该问题,我使用Nsight Compute的GPU Trace Profiler来查看glGenerateMipmap执行时GPU的占用情况。
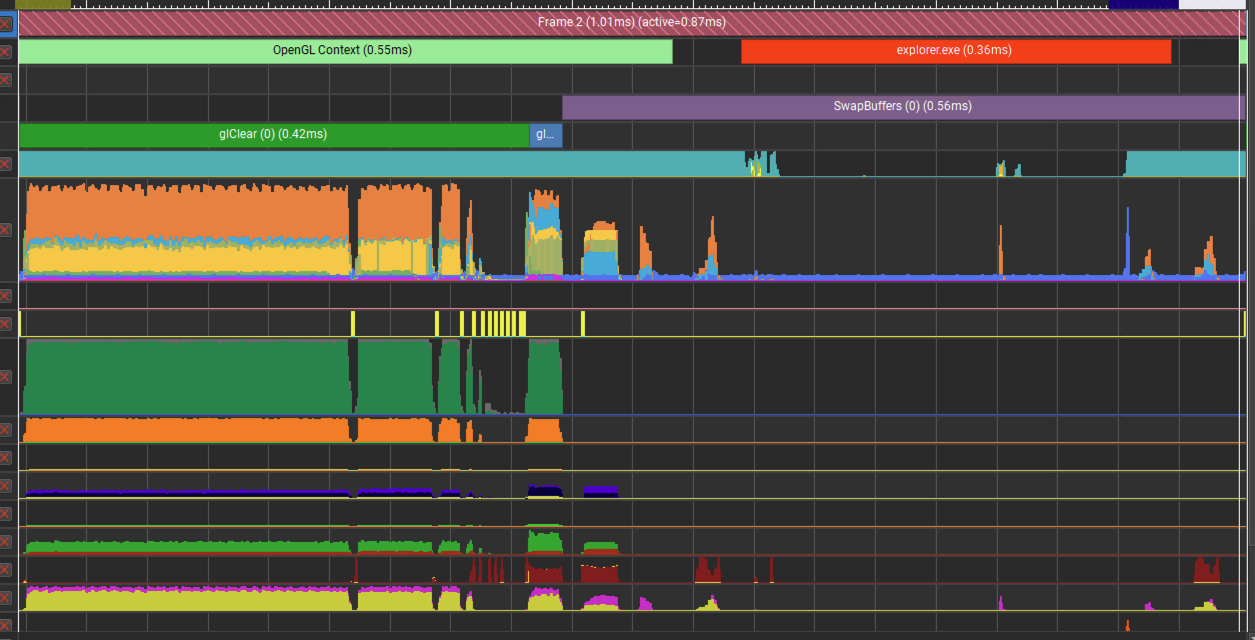
图 7:第二帧时glGenerateMipmap执行时GPU的占用情况。
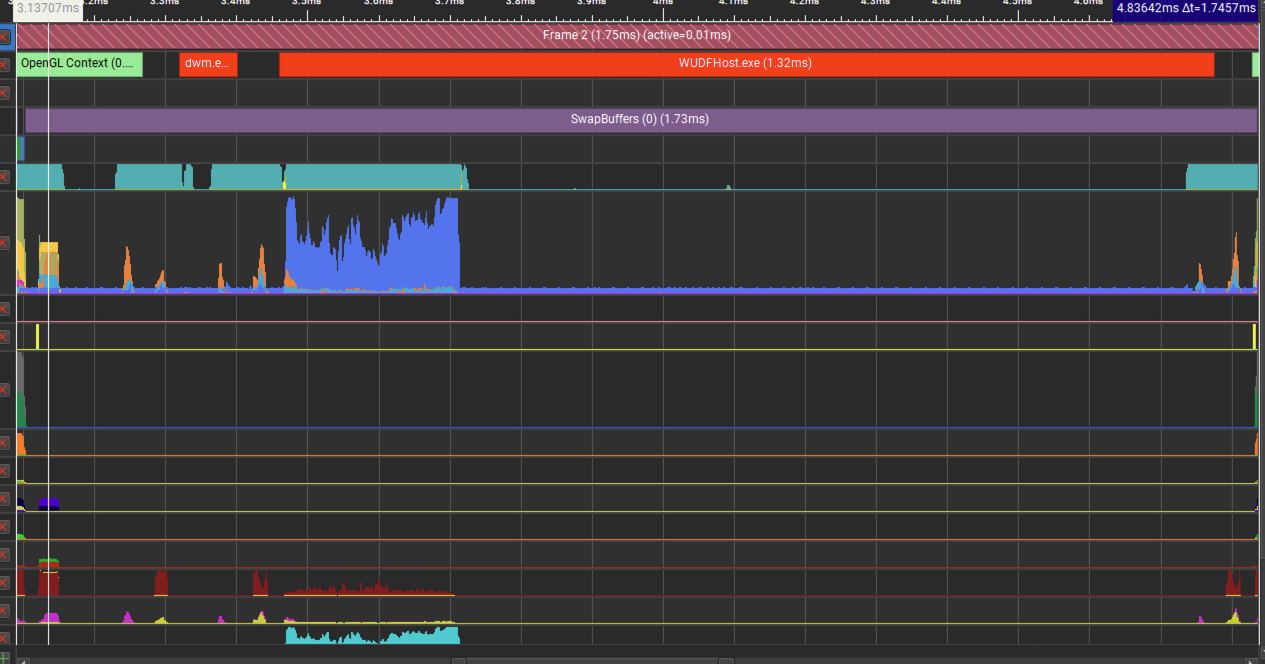
图 8:第二帧时不调用glGenerateMipmap时GPU的占用情况。
从图中可以看出,glGenerateMipmap执行时和不调用该函数相比,GPU的占用率明显更高,因此第二帧时glGenerateMipmap的调用时只有CPU侧的部分资源分配任务被跳过,GPU侧的任务没有明显变化。
区域平均
上述借助双线性插值的方法本质上都是一个“逐级”的过程,这其中驱动层面上会产生额外的开销。并且,数据在GPU的主存和片上内存之间来回传输,存在IO开销。
区域平均则是一个“单次”的过程,它通过一次计算过程将图像直接降采样到任意目标尺寸,而不需要多次迭代。
然而,区域平均无法像双线性插值利用硬件特性,需要我们自己实现。
一种最直接的方法是在片段着色器中读取NxN的像素,然后计算平均值。然而,数据的读取和累加操作是在单个片段着色器中顺序执行的,计算效率低下。
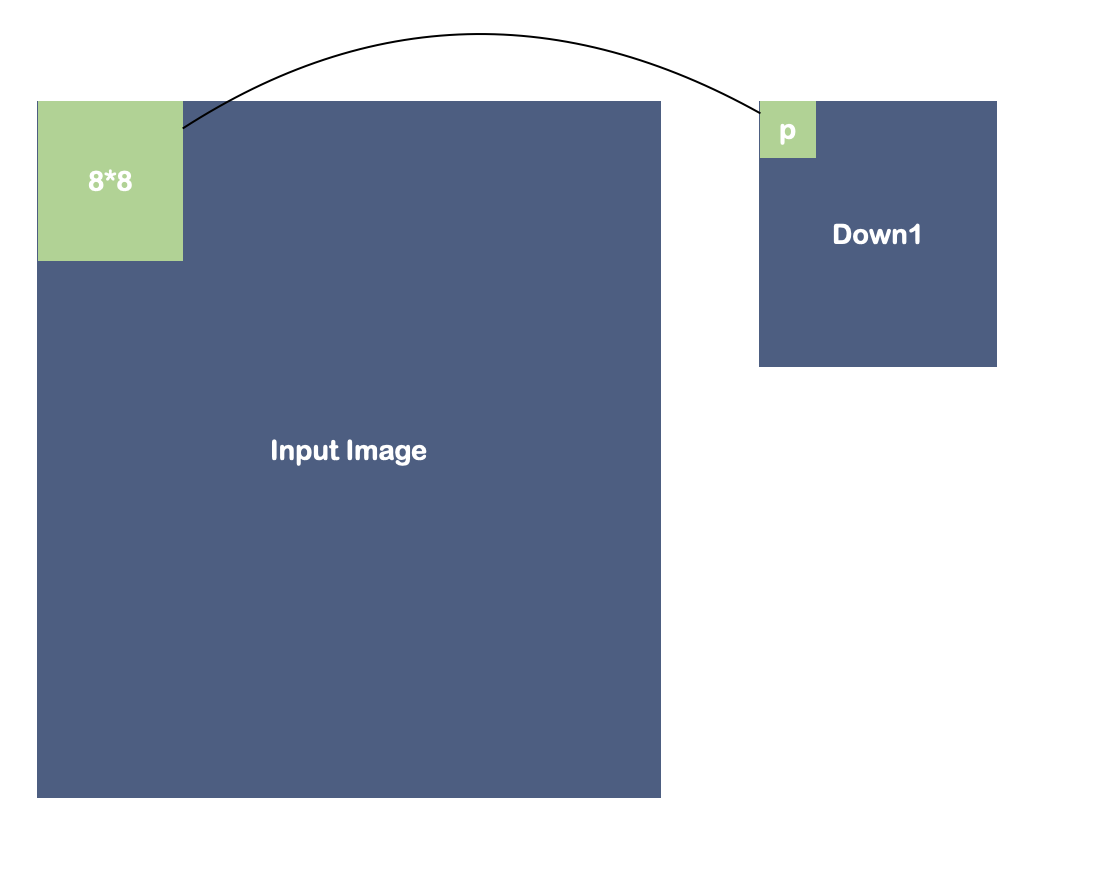
图 9:区域平均的计算过程。
使用Compute Shader
为了提高利用并行性,我们可以使用Compute Shader来进行区域平均。
算法实现:
1.每个线程读取32个像素。
2.在线程内部计算列方向上的求和,根据降采样比率决定累加的数据数量。
3.将中间结果写入恭喜那个内存中。
4.LandID<output_size*output_size的像素读取m个共享内存中的数据。
5.计算行方向上的累加并写入输出图像中。
每个warp中包含32个线程,因此一个Warp处理32*32的区域,如下图所示:
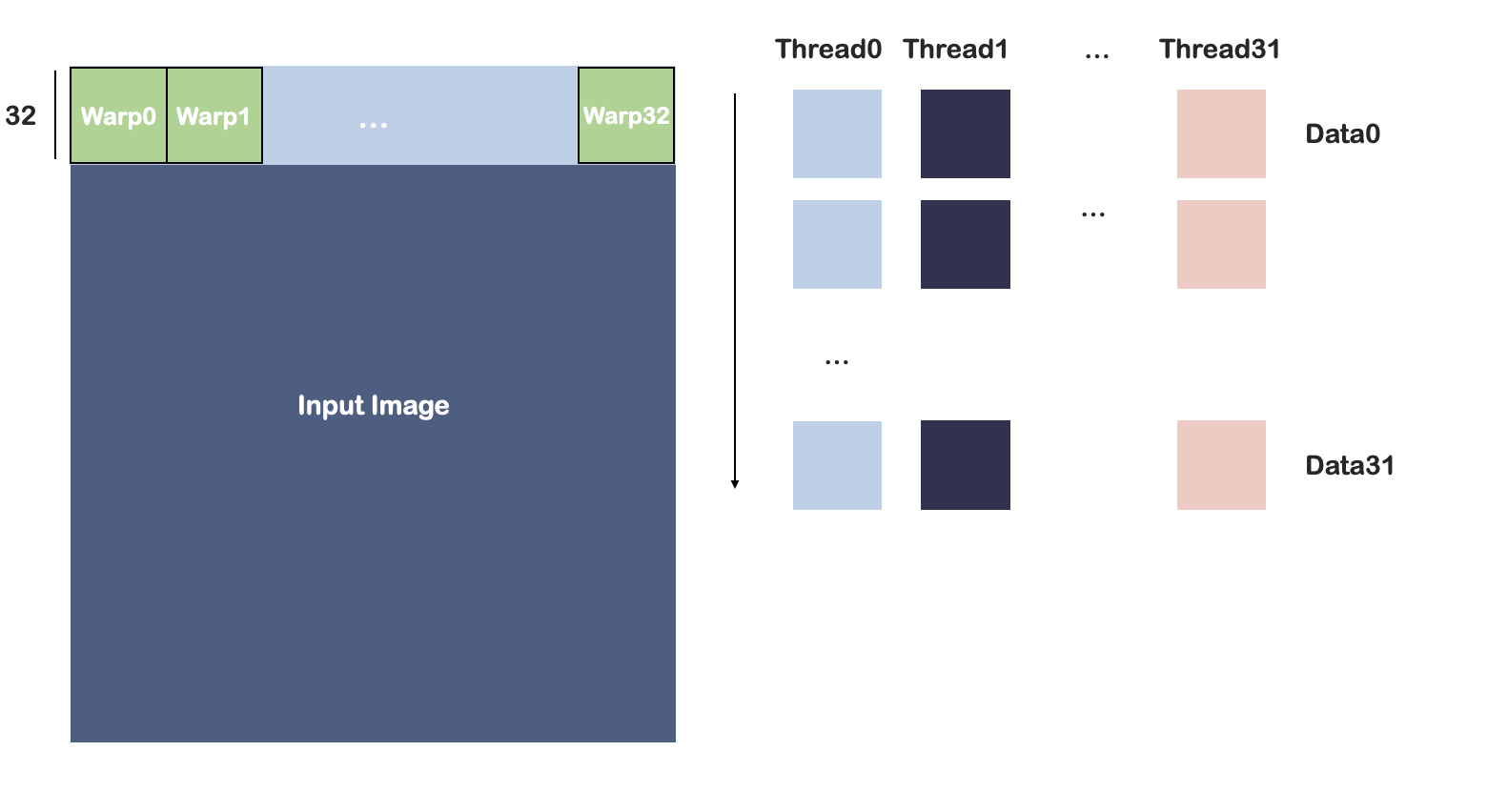
图 10:Warp处理32*32的区域,每个线程读取32个数据。
为了简化过程,我们以4*4的区域为例(假设一个warp中只包含4个线程,每个线程读取4个数据),进行讲解。下采样比率为2,即输出图像的分辨率为输入图像的$\frac{1}{2}$ 。
读取数据
线程根据所在的workgroupID,WarpID,以及线程ID,计算出该线程需要读取的像素的坐标,然后读取这些像素的值到寄存器中。
计算列方向上的求和
列方向上的输出维度为2,因此每$\frac{4}{2}$个像素进行一次累加。
写入共享内存
将中间结果写入共享内存中。
读取共享内存
LandID<2*2的线程读取共享内存中的结果到寄存器。
计算行方向上的累加
计算行方向上的累加并写入输出图像中。
累加过程如图所示:
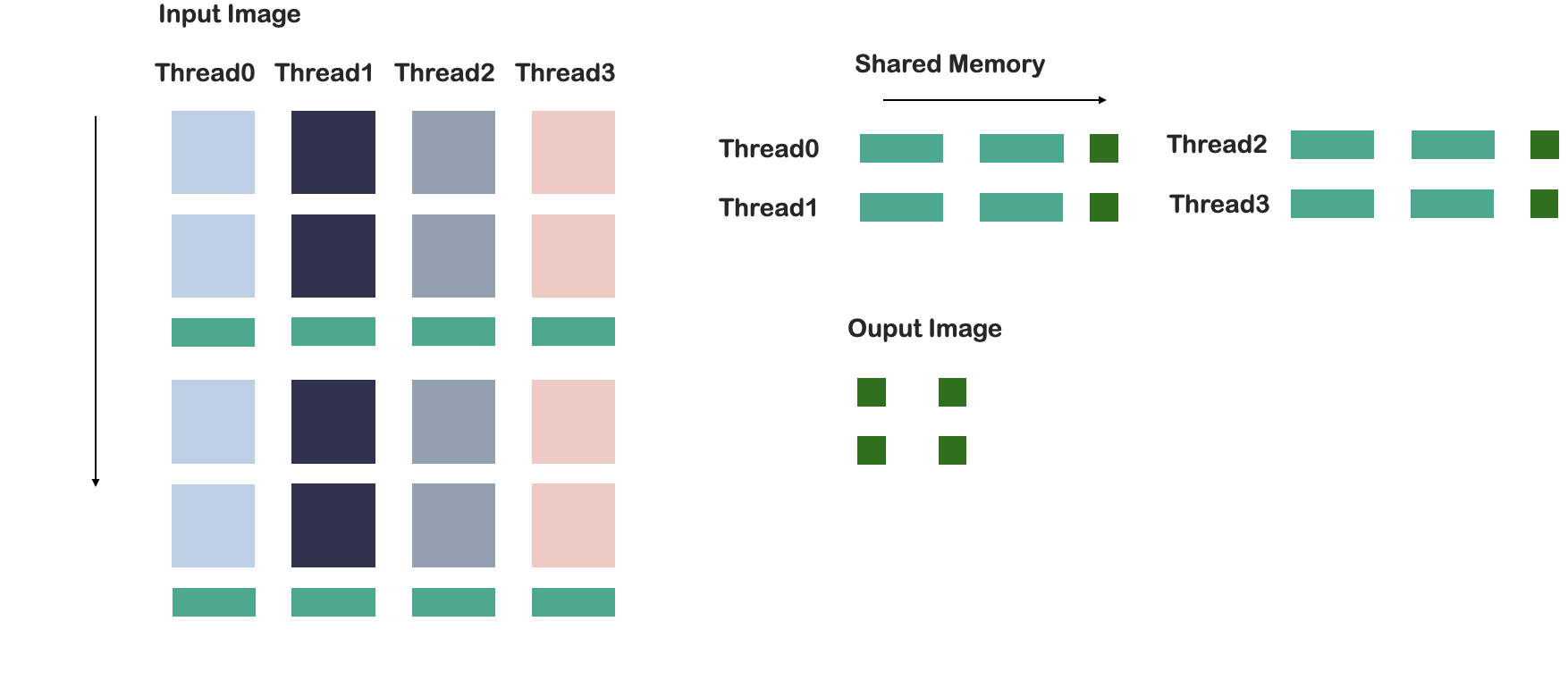
图 11:累加流程。
实验结果
输入2048*2048的图像,降采样到64*64。
| 方法 | CPU时间(ms) | GPU时间(ms) |
|---|---|---|
| glGenerateMipmap | 2.4 | 2.1 |
| 逐级降采样 | 9.3 | 1.5 |
| Vulkan Mipmap | 1.8 | 1.5 |
| 区域平均(CS) | 0.9 | 0.9 |