
Vulkan中的std140布局:从原理到实践
1. 引言
在Vulkan开发中,shader与CPU端数据交互是一个常见需求。然而,由于GPU和CPU的内存布局规则可能不同,如果不注意数据对齐,很容易导致数据访问错误。本文将详细介绍std140布局规则,帮助你正确处理Vulkan中的uniform buffer数据。
2. 内存对齐基础
2.1 为什么需要内存对齐?
内存对齐主要有两个目的:
- 确保数据访问效率
- 满足硬件访问要求
在Vulkan中,不同的buffer类型有不同的对齐要求:
- Uniform Buffer Objects (UBO) : 必须使用std140布局
- Storage Buffer Objects (SSBO) : 可以使用更宽松的std430布局
3. std140布局规则详解
3.1 基本类型对齐规则
layout(std140, binding = 0) uniform UBO {
float a; // 4字节对齐
double b; // 8字节对齐
int c; // 4字节对齐
bool d; // 4字节对齐
};
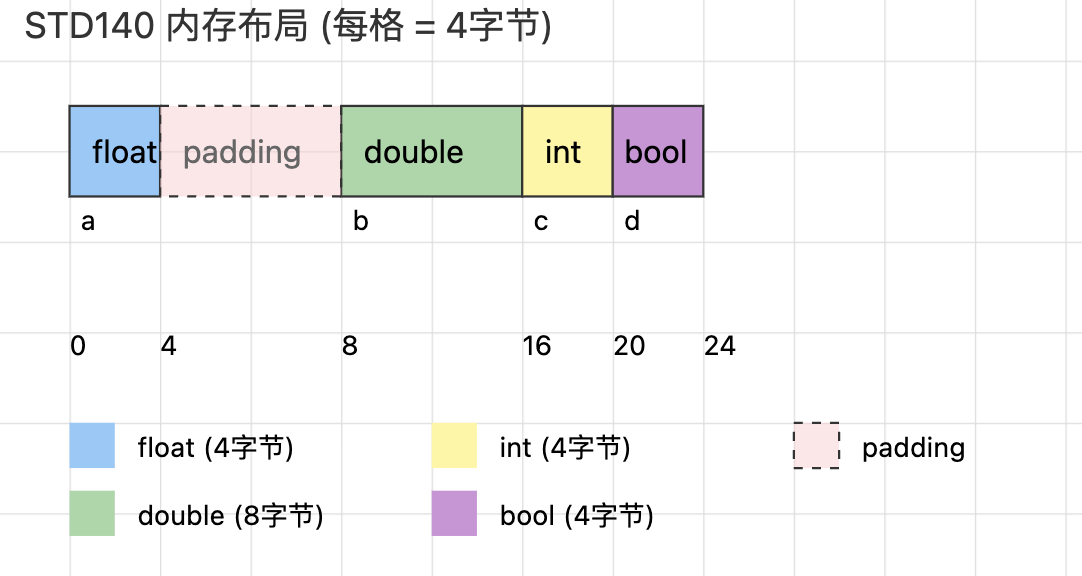
图 1:UBO对齐
3.2 向量类型对齐
shader中的定义:
layout(std140, binding = 0) uniform UBO {
vec2 a; // 8字节对齐
vec3 b; // 16字节对齐
vec4 c; // 16字节对齐
};
在CPU侧定义时,需要显式的加入padding或使用特殊方式:
- 使用Padding:
struct UBO {
struct Vec2 {
float x;
float y;
float padding[2]; // 补充到16字节
} a; // vec2 a
struct Vec3 {
float x;
float y;
float z;
float padding; // 补充到16字节
} b; // vec3 b
struct Vec4 {
float x;
float y;
float z;
float w;
} c; // vec4 c
};
- 使用glm。
struct UBO {
glm::vec2 a; // glm中的向量自动应用了对齐原则
glm::vec3 b; // 对齐到16字节
glm::vec4 c;
};
- 使用alignas关键字:
struct UBO {
alignas(8) Vec2 a;
alignas(16) Vec3 b;
alignas(16) Vec4 c;
};
3.3 数组对齐规则
在std140中,数组元素有特殊的对齐要求:
- 每个元素都会对齐到16字节(vec4的大小)
- 即使是基本类型的数组也遵循这个规则
// 着色器代码
layout(std140, binding = 0) uniform UBO {
float values[4]; // 每个float占用16字节
};
C++对应代码:
struct UBO {
struct ArrayElement {
float value;
float padding[3]; // 添加填充至16字节
} values[4];
};
3.4 结构体对齐
结构体对齐需要遵循以下规则:
- 结构体起始位置按最大成员对齐(即对齐时按照最大成员对齐)
- 结构体大小必须是最大对齐要求的整数倍
- 成员按各自的对齐规则对齐
struct Data {
float a; // offset 0
vec2 b; // offset 8 (需要8字节对齐)
float c; // offset 16
vec3 d; // offset 32 (需要16字节对齐)
};
layout(std140, binding = 0) uniform UBO {
Data data;
};

图 2:结构体对齐
C++对应代码:
struct Data {
float a; // 0-4
float padding1[1]; // 4-8
alignas(8) glm::vec2 b; // 8-16
float c; // 16-20
float padding2[3]; // 20-32
alignas(16) glm::vec3 d; // 32-48
};
如果是Data[ ],那么Data[1]将从48字节开始。
4. 常见陷阱与解决方案
4.1 vec3的陷阱
在std140中,vec3会被当作vec4处理:
// 错误示范
struct BadLayout {
glm::vec3 position; // 可能导致错误的内存访问
float value;
};
// 正确示范
struct CorrectLayout {
alignas(16) glm::vec3 position; // 确保16字节对齐
float value;
float padding[3]; // 添加必要的填充
};
4.2 数组步长问题
// 错误示范
struct BadArray {
float values[4]; // 不会自动满足std140布局
};
// 正确示范
struct CorrectArray {
struct {
float value;
float padding[3];
} values[4]; // 每个元素16字节对齐
};
5.alignas关键字
C++11引入的alignas说明符是我们精确控制内存布局的利器:
struct ProblematicStruct {
float a; // 4字节
vec3 b; // 16字节对齐 ← 问题根源!
};
// 使用alignas修正版
struct AlignedStruct {
alignas(16) float a; // 强制16字节对齐
vec3 b; // 现在安全了
};
alignas的注意事项:
- 指定值必须是2的幂次
- 不能小于类型的自然对齐要求
- 对结构体使用时影响整个结构体的对齐
6.最佳实践思路:从shader确定对齐方式
[Shader Uniform Block] → [分析成员对齐] → [生成C++结构] → [验证字节偏移]
实战案例:
GLSL定义:
layout(std140) uniform MatrixBlock {
mat4 projection; // 偏移0
mat3 orientation; // 偏移64(4*4*4)
float opacity; // 偏移64 + 48 = 112
};
对应的C++结构:
struct MatrixBlock {
// mat4 = 4个vec4
alignas(16) glm::vec4 proj[4]; // 偏移0-63
// mat3需要视为3个vec4
alignas(16) glm::vec4 orient[3]; // 每个vec4存储vec3+padding
// 偏移64-111
alignas(16) float opacity; // 偏移112-127
// 总大小128字节(必须为16的倍数)
};
调试技巧:
// 使用offsetof验证每个成员的偏移量
static_assert(offsetof(MatrixBlock, opacity) == 112,
"Alignment check failed!");
7.一个关于共享内存的bug
背景说明
在现代GPU架构中,共享内存(Shared Memory)是一项关键资源,主要用于加速内存访问和提高数据复用率。然而,共享内存的使用并非无限,每款GPU都设定了其最大共享内存限制。这一限制直接影响到着色器程序的性能和稳定性。以NVIDIA RTX 1650为例,其共享内存容量为48KB。
在开发过程中,我在计算着色器中声明了一个共享内存数组:
shared vec3 sMem[3][32][33];
理论上,该数组的大小为3 * 32 * 33 * sizeof(vec3),即38,016字节(约37.125KB),并未超过RTX 1650的共享内存限制。此外,在编写和调试过程中,Vulkan验证层并未提示任何关于共享内存超限的错误信息。然而,当程序运行到特定阶段时,却意外地发生了崩溃。
问题根源
经过进一步查阅资料和深入分析,共享内存也需要遵守std140布局规则,vec3类型的数据会被当作vec4来对齐。因此,上述声明的共享内存实际上等同于:
shared vec4 sMem[3][32][33];
这样一来,实际占用的内存大小为3 * 32 * 33 * sizeof(vec4),即50,688字节(约49.5KB),已经超过了RTX 1650的最大共享内存限制。在程序运行时,由于超出共享内存的限制,导致数据访问异常,最终引发了崩溃。