
Reference
P.A. Minerva’s Vulkan Tutorial on Compute Shaders
vulkan tutorial
AMD opengpu
GPU Program Blog
Example for Compute Shader
Intro
-
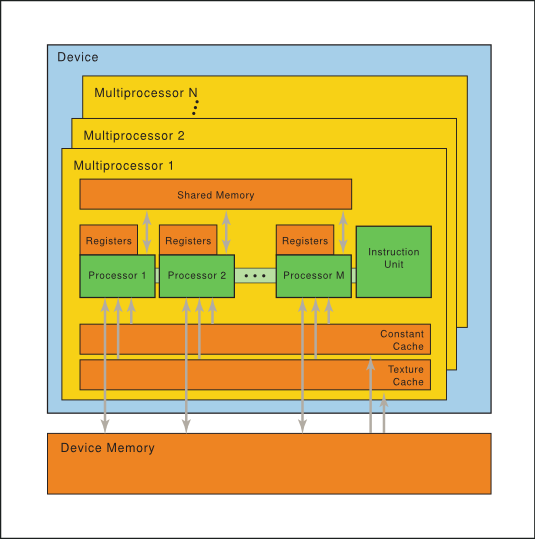
核心组成:GPU由数千个处理核心组成,这些核心专门用于执行由许多核心同时处理的单独任务。GPU通过并行执行相同的指令序列(描述特定任务)来实现高速处理大量数据。
-
核心组织:这些核心被组织成多处理器(multiprocessors),能够在多个线程上并行执行相同的指令。这种硬件模型被称为SIMT架构(Single-Instruction, Multiple-Thread)。
-
多处理器内存:每个多处理器包括以下几种类型的片上内存:
- 32位寄存器,分配给核心。
- 共享内存,由所有核心共享。
- 只读常量缓存,加速从设备内存的只读区域读取。
- 只读纹理缓存,加速从纹理内存空间读取。
-
线程组和执行:多处理器创建、管理、调度并执行称为warp(或wavefront)的32或64个并行线程组。每个warp在同一程序地址开始,但具有自己的指令地址计数器和寄存器状态,因此可以独立分支和执行。
-
线程块和warp调度:多处理器接收一个或多个线程块进行执行时,将它们划分为warps,并由warp调度器管理和调度。线程块到warp的划分是一致的,每个warp包含连续递增的线程ID。
-
执行上下文和调度:每个warp的执行上下文在其整个生命周期内都保持在芯片上,因此从一个执行上下文切换到另一个没有成本。每个指令发出时,warp调度器可以选择一个准备好执行下一指令的warp,并向这些线程发出指令。
线程块(Thread Blocks)
- 定义:线程块是一组在GPU上同时执行的线程。它是由程序员定义的,用于组织和执行并行任务。
- 大小和形状:线程块的大小(即包含的线程数)和形状(如1D、2D或3D)可以根据特定的计算任务进行调整。
- 资源共享:线程块内的线程可以共享一定量的快速访问内存(称为共享内存),并且可以进行同步操作。
Warp(线程束)
- 定义:warp是线程块中的一小部分线程,这些线程在GPU上以单一的指令流同时执行相同的操作。在NVIDIA的GPU中,一个warp通常包含32个线程。
- 硬件调度单位:warp是GPU硬件调度和执行的基本单位。GPU的warp调度器负责管理这些warp的执行。
线程块与Warp之间的关系
- 线程块划分为Warp:当线程块被提交到GPU执行时,它被划分为多个warp。这个划分是自动进行的,基于warp的大小(如32个线程)。
- 连续线程ID:每个warp包含具有连续线程ID的线程。例如,在32线程的warp中,第一个warp包含线程ID 0-31,第二个warp包含线程ID 32-63,依此类推。
- 并行执行:线程块内的所有warp可以在GPU上并行执行,但每个warp内的线程同时执行相同的指令。
- 执行效率:合理地组织线程块和warp对于实现高效的GPU并行计算至关重要。线程块的大小应该是warp大小的整数倍,以最大化GPU核心的利用率并减少空闲线程。
SIMD vs SIMT
GPU并不提供对SIMD的支持,因此考虑并行应该是SIMT,多个线程执行相同的指令。
GPU可以理解为一系列Multiprocessor的集合,如上图。Multiprocessor内部的processor可以共享一部分数据。
因此线程组的数量应该和multiprocessor数量对应(线程组可以多于multiprocessor数量)。
而warp是一组线程,是最小的调度单位。warp内的线程并行执行,但不同的warp之间是否并行取决于资源的分配(实际上这是由于某些操作会被挂起等待,转而执行其他的warp)。
CS
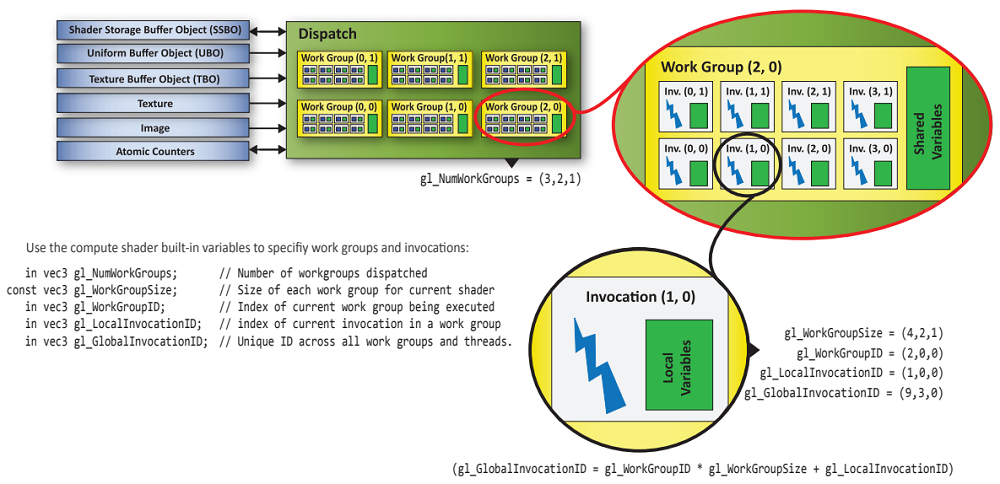
Thread Blocks:一个三维逻辑结构
Coding
Check maxComputeWorkGroupInvocations and maxComputeWorkGroupSize in VkPhysicalDeviceLimits
查询线程组数量和线程组大小限制
线程组的数量由API制定,线程组的大小在GLSL代码中被指定
Sync
共享内存
// Array allocated in shared memory to be shared by all invocations in a work group.
// Check VkPhysicalDeviceLimits::maxComputeSharedMemorySize for the maximum
// total storage size, in bytes, available for variables shared by all invocations in a work group.
shared vec4 gCache_0[256];
在一个线程组中的线程的执行很难确定先后顺序,如果多个线程访问到相同的数据,可能会造成线程冲突。
void main()
{
ivec2 textureLocation = ivec2(gl_GlobalInvocationID.xy);
// Read texel from input image at mipmap level 0 and
// save the result in the shared memory
gCache_0[gl_LocalInvocationID.x] = imageLoad(InputTex, textureLocation);
// Wait for all invocations in the work group
barrier();
// OK!
vec4 left = gCache_0[gl_LocalInvocationID.x - 1];
vec4 right = gCache_0[gl_LocalInvocationID.x + 1];
// ...
}
使用屏障保证数据写入完成。
barrier()函数的作用
- 同步工作组内的着色器调用:在计算着色器中,
barrier()函数确保在一个工作组(workgroup)内的所有着色器调用都到达这个屏障点之前,任何一个着色器调用都不会继续执行超过这个点的代码。 - 在曲面细分控制着色器中的应用:
barrier()函数也可以在曲面细分控制着色器中使用,以同步单个输入补丁的所有着色器调用。
控制流的一致性
- 控制流必须是一致的:在计算着色器中使用
barrier()时,控制流必须是一致的。这意味着如果任何一个着色器调用进入了一个条件语句,那么所有的调用都必须进入它。
barrier()与内存同步
- 控制流和共享变量的同步:
barrier()函数影响控制流,并同步对共享变量的内存访问(以及曲面细分控制输出变量)。 - 其他内存访问:对于非共享变量的内存访问,
barrier()函数并不能保证一个着色器调用在barrier()之前写入的值可以被其他调用在barrier()之后安全地读取。
使用内存屏障函数
- 确保内存访问的顺序:为了确保一个着色器调用写入的值可以被其他调用安全地读取,需要同时使用
barrier()和特定的内存屏障函数。 - 内存屏障函数的作用:内存屏障函数用于对可被其他着色器调用访问的内存中的变量进行读写操作的排序。这些函数在被调用时,会等待调用者之前执行的所有读写操作的完成,然后再返回。
不同类型的内存屏障函数
- 特定类型变量的内存屏障:如
memoryBarrierAtomicCounter()、memoryBarrierBuffer()、memoryBarrierImage()和memoryBarrierShared()等函数,分别用于等待对原子计数器、缓冲区、图像和共享变量的访问的完成。 - 全局内存屏障:
memoryBarrier()和groupMemoryBarrier()函数用于等待对所有上述变量类型的访问的完成。 - 着色器类型的可用性:
memoryBarrierShared()和groupMemoryBarrier()只在计算着色器中可用,而其他函数在所有着色器类型中都可用。
例子:粒子系统
使用GPU更新顶点位置,避免了受到总线带宽的限制。
SSBO
需要一个能读能写的buffer,SSBO可以满足这一点。
flag为:
VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT
VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT
Buffer type
. VK_BUFFER_USAGE_STORAGE_BUFFER_BIT
• Description: This flag indicates that the buffer can be used as a storage buffer. Storage buffers are used to store large blocks of data that shaders (especially compute shaders) can read from and write to.
• Common Use Case:
• It is commonly used in compute shaders or fragment shaders where you need random-access read and write operations.
• It’s suitable for large datasets that may change frequently, like results of computations or intermediate data.
• Access in Shaders:
• In GLSL (Vulkan’s shading language), a buffer marked with VK_BUFFER_USAGE_STORAGE_BUFFER_BIT is typically accessed using the layout(std430) storage qualifier, like this:
• Both read and write operations are possible in shaders.
VK_BUFFER_USAGE_TRANSFER_SRC_BIT
• Description: This flag indicates that the buffer can be used as a source for data transfer operations. Specifically, this buffer can be used in a memory transfer operation, where data from this buffer will be copied to another buffer or image (e.g., via vkCmdCopyBuffer or vkCmdCopyBufferToImage).
• Common Use Case:
• When you want to copy data from one buffer to another buffer or image, the source buffer should be created with this flag.
• It’s useful when you’re doing staging operations: you might upload data to a buffer that’s visible to the CPU (with VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT), then transfer it to a GPU-only buffer with VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT.
VK_BUFFER_USAGE_VERTEX_BUFFER_BIT用于顶点着色器,VK_BUFFER_USAGE_STORAGE_BUFFER_BIT用于计算着色器的写入和读取。
VK_BUFFER_USAGE_TRANSFER_DST_BIT表明该buffer是数据复制的目的buffer。例如从staging buffer到该buffer。
VK_BUFFER_USAGE_TRANSFER_SRC_BIT表明该buffer是数据复制的起源。例如staging buffer。
Storage Image
借助SI可以完成对图片的操作,例如后处理、生成mip-maps等。
信号量和栅栏
计算cmd需要栅栏避免冗余提交(确保之前的
指令已经被执行再提交,cpu和gpu之间),计算管线和图形管线之间需要信号量,保证图形管线开始时计算任务已经完成(gpu内部)。
[!note]
解释了为什么信号量以数组形式给出:
VkSemaphore waitSemaphores[] = { computeFinishedSemaphores[currentFrame], imageAvailableSemaphores[currentFrame] };
延伸:
Asynchronous compute
[[TBDR]]