
命令池与命令缓冲区
在Vulkan的渲染架构中,命令池(Command Pool)和命令缓冲区(Command Buffer)构成了GPU指令管理的核心机制。
命令池 (Command Pool): 命令池是命令缓冲区的内存分配器和管理器。你可以把它想象成一个命令缓冲区的“工厂”。 每个命令池都与一个特定的队列族索引 (Queue Family Index) 关联。这意味着从该命令池分配的命令缓冲区只能提交到与该队列族索引对应的队列中。
- 内存分配: 命令池负责分配命令缓冲区所需的内存。Vulkan 允许驱动程序在命令池级别进行内存管理优化,例如预分配内存,从而提高命令缓冲区分配和释放的效率。
- 生命周期管理: 命令池管理着它所分配的命令缓冲区的生命周期。你可以重置整个命令池,一次性释放所有命令缓冲区,也可以单独重置和重新使用命令缓冲区。
命令缓冲区 (Command Buffer): 命令缓冲区是实际存储 GPU 指令的容器。它记录了一系列图形或计算操作,例如:
- 渲染指令: 设置渲染状态、绑定描述符集、绑定顶点缓冲区和索引缓冲区、绘制调用等。
- 计算指令: 分发计算着色器、绑定计算描述符集等。
- 传输指令: 缓冲区和图像的拷贝、填充、更新等。
- 同步指令: 设置事件、栅栏、管线屏障等。
可以将命令缓冲区类比为一条“指令流水线”,GPU 会按照命令缓冲区中指令的顺序逐条执行。
| 特性 | 命令池 | 命令缓冲区 |
|---|---|---|
| 生命周期管理 | 手动创建/销毁 | 由命令池分配/回收 |
| 线程关联性 | 绑定到特定队列族 | 继承所属命令池的队列族属性 |
| 重置行为 | 可批量重置所有关联命令缓冲区 | 支持单独或批量重置 |
| 内存管理 | 控制底层内存分配策略 | 使用预分配的内存空间 |
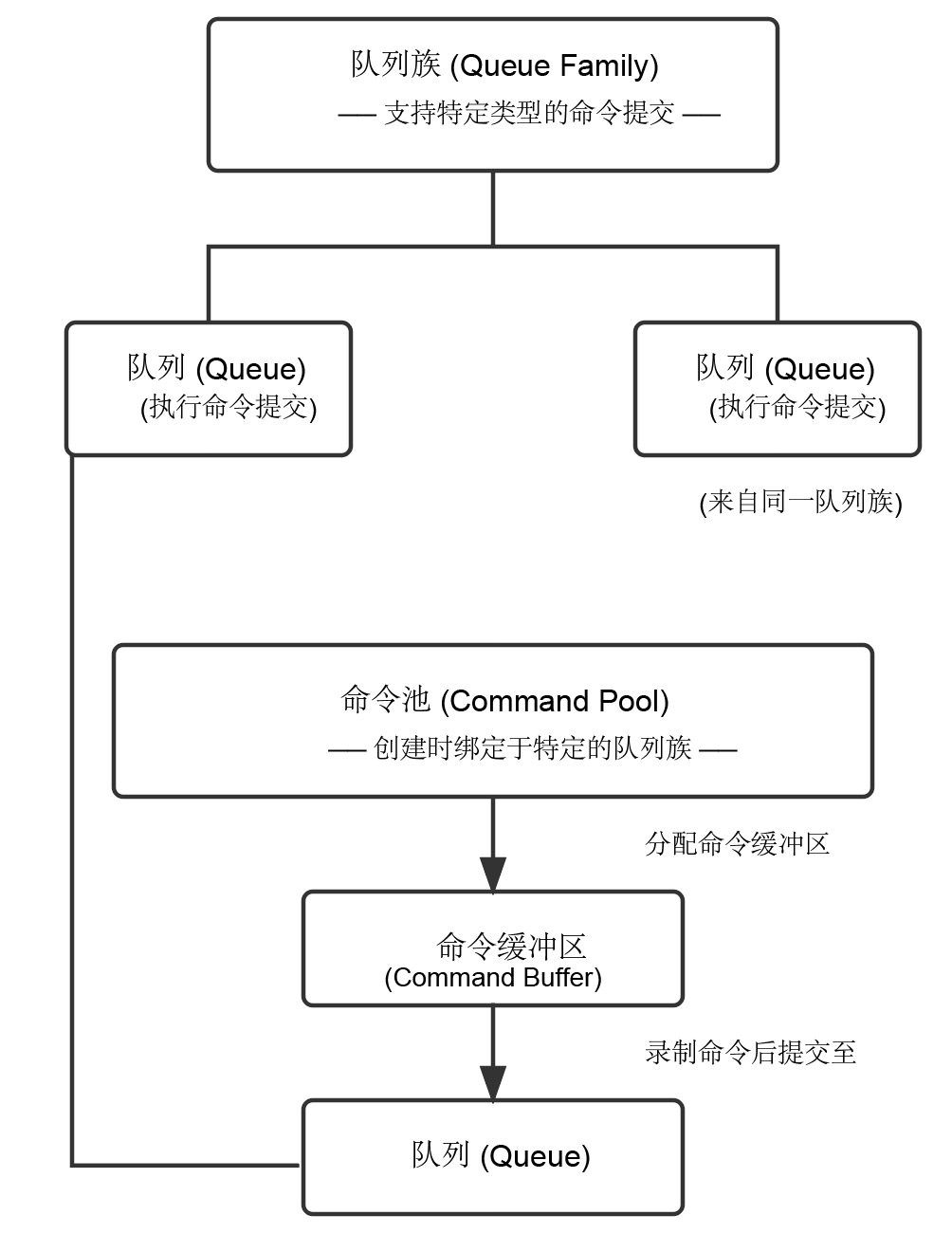
图 1:CommandPool 、CommandBuffer 、QueueFamily 、 Queue 的关系。
回顾在Vulkan初始化中,我们提到命令池创建时需要指定队列族,由该命令池创建的命令缓冲区也只能使用该队列族的队列来执行。
创建和使用
命令池创建
VkCommandPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
poolInfo.queueFamilyIndex = queueFamilyIndex; // 指定队列族索引 (例如图形队列族)
poolInfo.flags = VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT;
vkCreateCommandPool(device, &poolInfo, nullptr, &commandPool);
标志位解析:
VK_COMMAND_POOL_CREATE_TRANSIENT_BIT: 适用于高频更新的短期命令。提示驱动程序命令缓冲区是短暂的,可能可以进行一些优化,但实际效果取决于驱动程序。
VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT: 允许单独重置命令缓冲区。强烈建议设置此标志位。它允许你单独重置命令池中分配的命令缓冲区,以便重复使用,而无需重新分配。
命令缓冲区分配
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY; // 或者 VK_COMMAND_BUFFER_LEVEL_SECONDARY
allocInfo.commandBufferCount = 1; // 分配的命令缓冲区数量
vkAllocateCommandBuffers(device, &allocInfo, &commandBuffer);
commandPool: 指定命令缓冲区从哪个命令池分配。
level: 指定命令缓冲区的级别,可以是 VK_COMMAND_BUFFER_LEVEL_PRIMARY 或 VK_COMMAND_BUFFER_LEVEL_SECONDARY。
commandBufferCount: 指定要分配的命令缓冲区数量。可以一次性分配多个命令缓冲区。
开始和结束记录
VkCommandBufferBeginInfo beginInfo{};
beginInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
beginInfo.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT; // 提示缓冲区将被提交一次并立即重置
vkBeginCommandBuffer(commandBuffer, &beginInfo);
// ... 在这里记录你的 Vulkan 指令 (例如 vkCmdBindPipeline, vkCmdDraw 等) ...
vkEndCommandBuffer(commandBuffer);
beginInfo.flags: 可以设置一些标志位来提示驱动程序命令缓冲区的用途,常用的标志位包括:
VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT: 提示缓冲区将被提交一次,然后立即重置或释放。VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT: 指示后续渲染通道的状态将继承自这个命令缓冲区之前的渲染通道。VK_COMMAND_BUFFER_USAGE_SIMULTANEOUS_USE_BIT: 指示命令缓冲区可以多次提交,直到被显式重置。
提交
记录完成的命令缓冲区需要提交到队列才能被 GPU 执行。
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffer;
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE) != VK_SUCCESS) {
throw std::runtime_error("failed to submit command buffer!");
}
// 可选: 等待队列完成执行 (同步操作)
vkQueueWaitIdle(graphicsQueue);
submitInfo.pCommandBuffers: 指向要提交的命令缓冲区数组。
vkQueueSubmit: 将命令缓冲区提交到指定的队列 (graphicsQueue 在这里是图形队列)。
vkQueueWaitIdle: 等待队列中的所有命令缓冲区执行完成。通常用于同步操作,例如等待渲染完成才能进行后续操作。
释放和重置命令缓冲区
使用完命令缓冲区后,你可以选择释放或重置它。
释放命令缓冲区: 将命令缓冲区返回给命令池,可以再次分配新的命令缓冲区。
vkFreeCommandBuffers(device, commandPool, 1, &commandBuffer);
重置命令缓冲区: 清除命令缓冲区中的所有指令,使其可以重新记录。重置操作比重新分配更高效。
vkResetCommandBuffer(commandBuffer, 0); // 或者 VK_COMMAND_BUFFER_RESET_RELEASE_RESOURCES_BIT
VK_COMMAND_BUFFER_RESET_RELEASE_RESOURCES_BIT: 提示驱动程序释放命令缓冲区内部使用的资源,可以节省内存,但可能会降低性能。
销毁命令池
当不再需要命令池时,需要销毁它,释放其占用的资源。
vkDestroyCommandPool(device, commandPool, nullptr);
高级用法-二级缓冲区被主命令缓冲区调用
Vulkan 将命令缓冲区分为两种级别:
-
主命令缓冲区 (Primary Command Buffer, VK_COMMAND_BUFFER_LEVEL_PRIMARY): 主命令缓冲区可以提交到队列执行,并且可以调用二级命令缓冲区。它通常用于组织应用程序的主要渲染或计算流程。
-
二级命令缓冲区 (Secondary Command Buffer, VK_COMMAND_BUFFER_LEVEL_SECONDARY): 二级命令缓冲区不能直接提交到队列执行, 必须由主命令缓冲区调用才能被执行。二级命令缓冲区常用于:
- 组织复杂的渲染流程: 将渲染流程分解成多个逻辑模块,每个模块用一个二级命令缓冲区表示,提高代码可读性和可维护性。
- 并行命令缓冲区记录: 多个线程可以并行记录二级命令缓冲区,然后由主命令缓冲区按顺序调用,利用多核 CPU 提升命令缓冲区记录效率。
- 命令复用: 对于一些重复使用的命令序列,可以将其记录到二级命令缓冲区中,然后在多个主命令缓冲区中复用,减少重复记录的工作。
调用二级命令缓冲区
步骤:
- 创建二级命令缓冲区: 按照之前的方法,创建一个 VK_COMMAND_BUFFER_LEVEL_SECONDARY 级别的命令缓冲区。
- 记录二级命令缓冲区: 在二级命令缓冲区中记录你希望复用或并行记录的命令序列。
- 在主命令缓冲区中调用二级命令缓冲区: 在主命令缓冲区的记录过程中,使用 vkCmdExecuteCommands 命令来调用二级命令缓冲区。
// 假设 primaryCmdBuffer 是主命令缓冲区,secondaryCmdBuffer 是二级命令缓冲区
vkBeginCommandBuffer(primaryCmdBuffer, &primaryBeginInfo);
// ... 主命令缓冲区中的其他指令 ...
// 调用二级命令缓冲区
vkCmdExecuteCommands(primaryCmdBuffer, 1, &secondaryCmdBuffer);
// ... 主命令缓冲区中的其他指令 ...
vkEndCommandBuffer(primaryCmdBuffer);
二级命令缓冲区的继承 (Inheritance)
当二级命令缓冲区在渲染通道内执行时,需要设置继承信息,例如渲染通道 (Render Pass) 和帧缓冲区 (Framebuffer)。这通过 VkCommandBufferInheritanceInfo 结构体在分配二级命令缓冲区时指定。
VkCommandBufferInheritanceInfo inheritanceInfo{};
inheritanceInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_INHERITANCE_INFO;
inheritanceInfo.renderPass = renderPass; // 继承的渲染通道
inheritanceInfo.framebuffer = framebuffer; // 继承的帧缓冲区
VkCommandBufferAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
allocInfo.commandPool = commandPool;
allocInfo.level = VK_COMMAND_BUFFER_LEVEL_SECONDARY;
allocInfo.commandBufferCount = 1;
allocInfo.pInheritanceInfo = &inheritanceInfo; // 设置继承信息
vkAllocateCommandBuffers(device, &allocInfo, &secondaryCmdBuffer);
- 当前 Render Pass:确保次级缓冲区的操作与主缓冲区的渲染流程兼容。
- 当前 Framebuffer:明确操作的目标附件(如颜色/深度附件)。
- 子通道(Subpass):若次级缓冲区在某个子通道内执行,需指定子通道索引。
Vulkan 会基于这些信息验证次级缓冲区的操作是否合法。如果未正确配置,可能导致验证层错误或运行时崩溃:
如果未正确配置,Vulkan 会抛出以下错误: - VUID-VkCommandBufferBeginInfo-flags-00053(Render Pass 未匹配)
- VUID-vkCmdExecuteCommands-pCommandBuffers-00088(Framebuffer 不兼容)
主命令缓冲会在记录时显式的在VkRenderPassBeginInfo中指定VkRenderPass和VkFramebuffer。
// 主缓冲区记录 Render Pass
VkRenderPassBeginInfo renderPassInfo{};
renderPassInfo.renderPass = myRenderPass; // 在此处指定 Render Pass
renderPassInfo.framebuffer = myFramebuffer;
vkBeginCommandBuffer(primaryCmdBuffer, ...);
vkCmdBeginRenderPass(primaryCmdBuffer, &renderPassInfo, VK_SUBPASS_CONTENTS_INLINE);
// 调用次级缓冲区或记录绘制命令
vkCmdEndRenderPass(primaryCmdBuffer);
vkEndCommandBuffer(primaryCmdBuffer);
高级用法-条件执行模式
代码逻辑
// 1. 定义可能执行的命令缓冲区(此处为两个候选)
VkCommandBuffer conditionalBuffer = ...;
// 2. 配置条件渲染信息
VkConditionalRenderingBeginInfoEXT condInfo{};
condInfo.sType = VK_STRUCTURE_TYPE_CONDITIONAL_RENDERING_BEGIN_INFO_EXT;
condInfo.buffer = conditionBuffer; // 存储条件值的缓冲区
condInfo.offset = 0; // 条件值在缓冲区中的偏移量
// 3. 开启条件渲染范围
vkCmdBeginConditionalRenderingEXT(primaryBuffer, &condInfo);
// 4. 在条件范围内执行命令
vkCmdExecuteCommands(primaryBuffer, 1, conditionalBuffer);
// 5. 结束条件渲染范围
vkCmdEndConditionalRenderingEXT(primaryBuffer);
解析
- 条件值的判定规则
GPU 会从 conditionBuffer 的指定 offset 处读取一个 32位无符号整数值。
判定逻辑:
若值 ≠ 0 → 执行条件范围内的命令
若值 = 0 → 跳过所有条件范围内的命令
-
执行范围的作用域
条件渲染的影响范围严格限定在 vkCmdBeginConditionalRenderingEXT 和 vkCmdEndConditionalRenderingEXT 之间的命令。
嵌套支持:Vulkan 允许条件渲染的嵌套使用,内层条件可以覆盖外层条件。 -
次级命令缓冲区的特殊性
示例中通过 vkCmdExecuteCommands 调用的次级命令缓冲区会整体受条件值控制。
若条件不满足,次级缓冲区的所有命令将被跳过,如同未被调用。
场景
- 动态遮挡剔除(Occlusion Culling)
// 步骤:
// 1. 第一帧:执行遮挡查询,将结果写入 conditionBuffer
// 2. 后续帧:根据查询结果决定是否绘制物体
vkCmdBeginConditionalRenderingEXT(cmdBuffer, &condInfo);
vkCmdDrawIndexed(cmdBuffer, ...); // 仅当物体可见时执行绘制
vkCmdEndConditionalRenderingEXT(cmdBuffer);
- 多方案动态切换
uint32_t conditionValue = useTechniqueA ? 1 : 0;
CopyDataToBuffer(conditionBuffer, &conditionValue); // 更新条件值
vkCmdBeginConditionalRenderingEXT(cmdBuffer, &condInfo);
if (useTechniqueA) {
vkCmdExecuteCommands(cmdBuffer, 1, &techACmdBuffer);
} else {
vkCmdExecuteCommands(cmdBuffer, 1, &techBCmdBuffer);
}
vkCmdEndConditionalRenderingEXT(cmdBuffer);
- GPU-Driven 渲染决策
// 通过计算着色器生成条件值
vkCmdDispatch(computeCmdBuffer, ...);
// 在渲染流程中根据计算结果决策
vkCmdBeginConditionalRenderingEXT(renderCmdBuffer, &condInfo);
vkCmdDraw(renderCmdBuffer, ...); // 由 GPU 计算的结果控制是否绘制
vkCmdEndConditionalRenderingEXT(renderCmdBuffer);
何时使用二级命令缓冲区?
1. 复杂场景分解
将复杂的渲染流程分解成多个二级命令缓冲区,例如将不同的物体或渲染阶段分别用不同的二级命令缓冲区表示,可以提高代码组织性。
2. 并行记录
如果你的应用程序有复杂的场景,命令缓冲区记录成为瓶颈,可以考虑使用多线程并行记录二级命令缓冲区,然后在一个主命令缓冲区中按顺序调用这些二级命令缓冲区。这可以有效利用多核 CPU 的性能。
3. 命令复用
对于重复使用的渲染或计算序列,将其记录到二级命令缓冲区中,在多个主命令缓冲区中复用,可以减少重复记录的工作量。
打包提交CommandBuffer
在Vulkan中,提交多个不同的command buffer到同一个队列与使用单个command buffer相比,性能差异主要受以下因素影响:
1. CPU开销
- 多次提交多个command buffer:
若每次提交均调用vkQueueSubmit(尤其是分散的多次调用),会增加CPU负担。驱动需要为每次提交处理验证、同步资源及命令传输,频繁的小批次提交可能导致CPU成为瓶颈。 - 单次提交单个command buffer:
减少vkQueueSubmit调用次数可降低CPU开销。驱动优化空间更大,可能合并内部操作,提升效率。
2. GPU执行效率
- 状态切换与批处理:
多个command buffer可能导致频繁的状态切换(如管线绑定、资源更新)。若这些command buffer未优化,GPU可能在执行时产生空闲。而单个command buffer可通过连续记录减少状态切换,提升吞吐量。 - 提交批次的影响:
GPU通常以提交批次为单位调度任务。多次提交可能分割任务,导致GPU无法充分并行;而单次提交(或一次提交多个command buffer)可能形成更大的批次,利于硬件优化。
3. 同步与依赖
- 显式同步需求:
多次提交常需依赖信号量或栅栏确保执行顺序,可能引入GPU等待。单次提交内部命令天然有序,减少同步需求,降低延迟。
4. 驱动与硬件的优化
- 驱动处理差异:
部分驱动可能优化多command buffer的合并执行(尤其在单次vkQueueSubmit提交多个时),性能接近单个command buffer。但多次分散提交可能无法享受此类优化。 - 硬件特性:
某些GPU架构更擅长处理大命令流,而小批次可能导致调度开销。
实践建议
- 优先减少提交次数:通过单次
vkQueueSubmit提交多个command buffer(而非多次调用),可平衡CPU/GPU效率,接近单一大command buffer的性能。 - 合并录制需权衡:若多个command buffer内容固定且需重用,分开录制可能更灵活;若内容动态变化,合并录制可能减少状态切换,但需评估CPU录制开销。
- 场景依赖:对实时渲染等高吞吐场景,倾向于减少提交次数与状态切换;对复杂依赖或并行录制需求,可接受适度性能损失以换取灵活性。
EasyVulkan中的CommandBuffer
在EasyVulkan中,使用CommandBufferBuilder来创建和记录命令缓冲区,在注册到ResourceManager中时,会绑定对应的CommandPool。即name-> (CommandBuffer,CommandPool)
例如创建单个CommandBuffer:
// 假设 graphicsPool 已经正确创建并初始化
auto cmdBuffer = commandBufferBuilder
->setCommandPool(graphicsPool)
->setLevel(VK_COMMAND_BUFFER_LEVEL_PRIMARY)
->build("mainCommandBuffer");
创建多个CommandBuffer:
// swapchainImageCount 为交换链图像数量
auto cmdBuffers = commandBufferBuilder
->setCommandPool(graphicsPool)
->setCount(swapchainImageCount)
->buildMultiple({"frame0", "frame1", "frame2"});
创建多个二级CommandBuffer:
// 假设 threadCount 是线程数量
auto secondaryCmdBuffers = commandBufferBuilder
->setCommandPool(graphicsPool)
->setLevel(VK_COMMAND_BUFFER_LEVEL_SECONDARY)
->setCount(threadCount)
->buildMultiple();